Loss Function
在 Linear Classifier 的训练过程中,我们可能会得到一系列的 W 值,而这些 W 的值会有不同的表现。这个时候我们希望能有一个函数来表示我们对这个 W 值的表现的满意程度。这个函数就是 Loss Function。
假设现在有数据集 ${(x_i, y_i)}_{i=1}^{N}$ ,其中 $x_i$ 是图片, $y_i$ 是(整数)标签,那么对这个数据集和当前 W 的 loss function 是:
$$L=\frac1N \Sigma_{i=1}^N L_i(f(x_i,W),y_i)$$
Multiclass SVM loss
一种 loss function 叫做 Multiclass SVM loss ,有如下的 $L_i$ 计算方式($s = f(x_i,W)$,$s_i$ 表示 $s$ 的第 $i$ 行): $$ L_i =\Sigma_{j\neq y_i} max(0, s_j - s_{y_i}+1) $$ 这里的 1 是设定的安全边际。公式对应的图像为:

这种 loss function 被称为 Hinge Loss ,在安全边际之前 loss function 线性降低,而之后其值为 0 。
计算这类 loss function 的 python 代码如下:
|
|
事实上仅仅通过这样的 loss function 很容易导致的一个问题就是训练得到的模型过于拟合训练数据,但实际上我们并不关心训练数据。我们希望它面对测试数据的时候也能有很好的表现。但是过于拟合训练数据的模型往往在面对新数据的时候表现并不好。如下图,蓝色点表示训练数据,蓝线表示拟合的模型(这不是线性的,是一个更一般的例子),绿色方块表示测试数据。可以看到尽管这条蓝线对蓝色点的拟合非常好,但是当面对绿色方块的时候,它的表现就不是那么优秀了。实际上我们更希望得到的是绿色的这条线。

对于这个问题,通常我们选择在 loss function 后再加一项 regularization ,这一项鼓励模型在训练的过程中选择更简单的那一种,以期在测试数据上得到更好的表现(由奥卡姆剃刀原理的思想),如下:
$L(W) = \frac1N \Sigma_{i=1}^N L_i + \lambda R(W)$
这里的 $\lambda$ 也是一个超参数,用于调整 $L_i$ 和 $R(W)$ 之间的比例。
一些常用的 $R(W)$如下:
| $R(W)$ | formula |
|---|---|
| L1 regularization | $R(W) = \Sigma_k \Sigma_l W_{k,l}^2$ |
| L2 regularization | $R(W) = \Sigma_k \Sigma_l |W_{k,l}|$ |
| Elastic net(L1 + L2) | $R(W) = \Sigma_k \Sigma_l \beta W_{k,l}^2+|W_{k,l}|$ |
| Dropout | … |
| … | … |
Softmax Loss
另一种计算方式是 Softmax ,这种计算方式如下:
$$P(Y=k | X = x_i) = \frac{e^{s_k}}{\Sigma_j e^{s_j}} \ \ \ \ \ s = f(x_i,W)$$
$$L_i = -logP(Y=y_i|X=x_i)$$
即:
$$L_i = -log(\frac{e^s{y_i}}{\Sigma_j e^{s_j}})$$
Softmax vs. SVM
两种 loss function 的计算过程示意图如下:
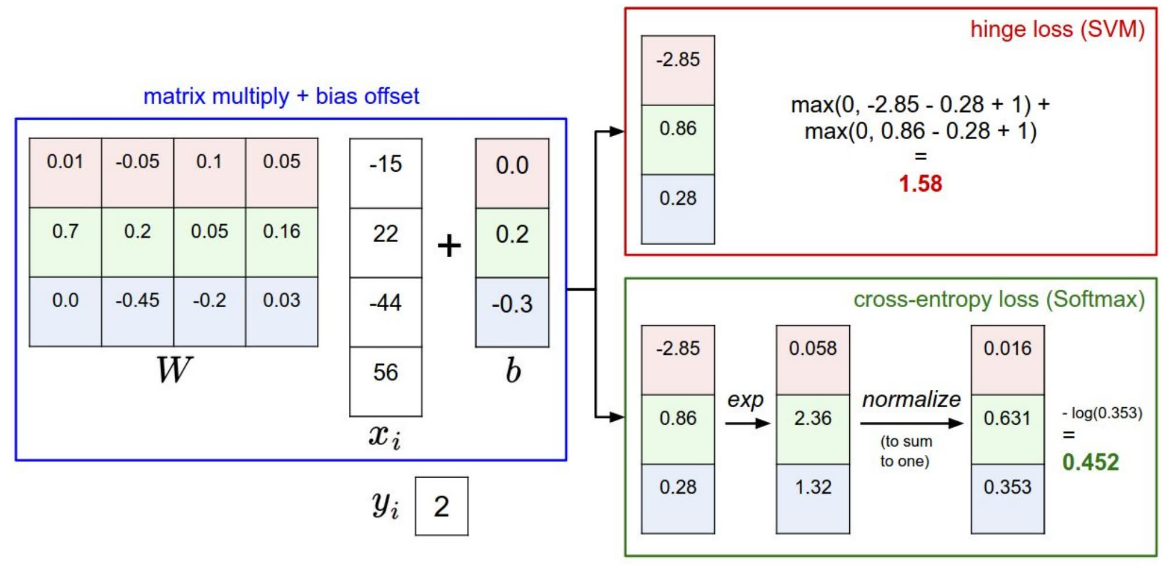
两者之间一个很大的区别在于,对于 SVM ,它关心的是正确分类的得分是否比其他得分高,只要正确得分确实比其他得分 + 安全边际要高,那么得到的 $L_i$ 就是 0 ,也就是说它的目标就是正确分类得分大于错误得分 + 安全边际。而对于 Softmax 而言,它总是希望正确分类的概率能够达到 1 ,也就是正确的得分趋向正无穷,而其他得分趋向负无穷(当然计算机对无穷的支持并不是那么优秀)。因此,不管现在训练的模型如何, Softmax 总是希望这个模型能够训练得更好。P. S. 从实际应用上来看两者并没有那么大的区别。
Optimization
那么,有了 loss function 以后,我们已经知道如何评估一个 W 矩阵的表现。那么,我们如何才能找到表现最优的那个 W 矩阵呢?
首先最容易想到的办法就是随机搜索,每次随机一个 W 矩阵,然后看这个矩阵表现如何,如果比当前最优的模型优那么就更新。显然,这种方法非常愚蠢,效率低下且训练结果也很难保证。
另一种想法是对于当前的 W 矩阵,我们试图去寻找其附近的局部最优解,并希望不断重复这个过程能够引领我们找到全局最优解。当然这很可能是找不到的,但即便如此,不断地找寻局部最优解这样的方法在实践中依然表现出了非常优秀的结果。
对 1 维的直线而言,寻找局部最优非常简单,只需要在当前位置的极限即可计算,如下:
$$\frac{df(x)}{dx} = \lim\limits_{h \rightarrow 0} \frac{f(x + h) - f(x)}{h}$$
而对多维而言,则需要用到梯度的概念。梯度是一个向量,其每一个维度的值是函数在这个维度的斜率。由数学推导可知,函数在一点沿梯度方向变化最大,也就是说可以利用梯度来求得局部最优的 W 矩阵。
在计算梯度的时候,也有两种不同的做法。一种是通过每次给 W 的一个维度加上一个很小的量,然后计算出两次 f(W)的值的差别,再除上这个很小的量,得到梯度在这个维度的值。这个方法的效率很低且精度有限,并不好。更好的方法是利用微积分的知识来求得梯度。当然数值计算的方法并非完全没有用,恰恰相反,利用数值计算来检验微分计算的正确性是很常见的手法,因为微分分析很容易出错。
有了梯度以后,我们便可以得到一个非常简短却是很多深度学习的核心思路的代码:
|
|
实际操作中还有一个小技巧。由于 loss function 的计算需要把所有数据的 loss 取平均,因此当数据量很大的时候每一次计算梯度都需要耗费非常多的时间。因此在计算梯度的时候,我们会考虑从所有的数据集中随机地取出一部分来代替所有数据,如下:
|
|
Image Features
事实上,由于多模态等原因,直接将图片像素信息不加任何处理地送进线性分类器,得到的结果往往不慎理想。因此在深度神经网络之前,人们往往采用两步来进行模型的训练。首先是将图片中的一些特征信息提取出来,计算得到数值,然后再把这些数值送进线性分类器。当然这个提取信息的过程需要根据图片信息而定。一个很简单的例子是在二维平面上的一些点。如果用经典的笛卡尔坐标系,则很难用线性分类进行区分;但如果进行特征提取转换为极坐标,那么就比较容易可以用线性分类器分开。

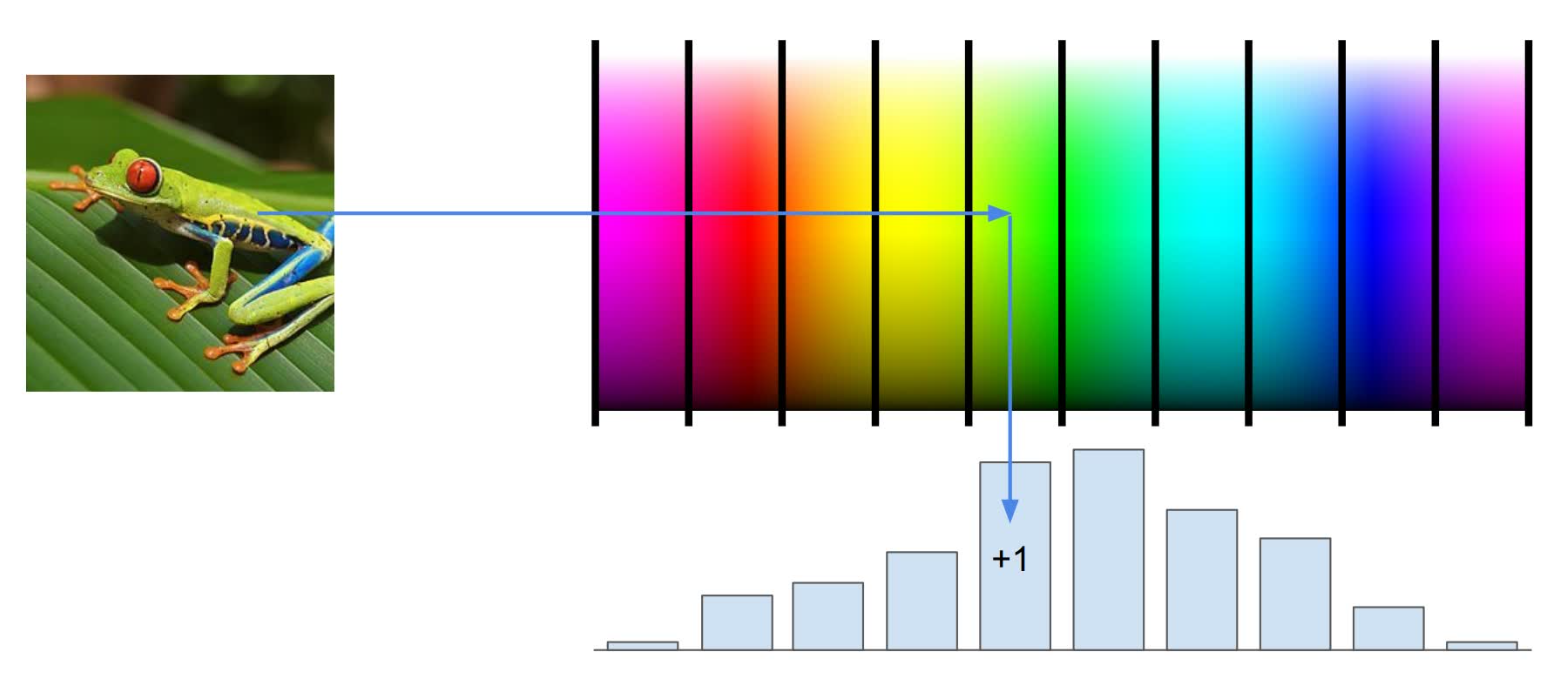
应用到实际中,一种常见的特征值提取叫做 Color Histogram (颜色直方图)。这种方法是将颜色大致分为几种,然后把每一个像素点的颜色按照分类计数。例如下图中的青蛙,得到的特征值中的绿色数量就占大多数。
还有一种很常见的特征值是 Histogram of Oriented Gradients 。上一讲有讲到边缘对视觉识别非常重要,因此提取边缘特征放进训练也是一种很好用的方法。例如把一张图分为 8 × 8 的小区域,每一个区域中有 9 个方向信息,这样一张 320 × 240 的图片就可以用 10800 个数来表示其边缘特征值。
